Roadmap
This is a glimpse into what we're working on and what we're planning to work on.
In progress
Edge caching
Dramatically speed up repeated queries by caching them on the edge. Enable with a simple parameter passed to the API and get end-user response times as low as 15 milliseconds.
Attachment type & image transformations
Upload images and other file attachments to your records. This includes a new rich type and the ability to make on-the-fly image transformations through the API and clients.
Sub-queries for linked records
Reverse queries and retrieve information from related tables in a single request. For instance, you can get a list of authors with their top-rated 5 blog posts in one network round-trip.
Custom filters and data privacy for data copying
Don’t let sensitive data make it into your dev branches. When copying data from the production branch to the dev branches, you’ll be able to set filters and mark columns as private.
SQL support
Query and update your data using SQL support. This will allow you to do the more complicated queries that are not possible with the REST API.
Planned
JSON column type
Sometimes it’s a just more convenient to go schemaless. The JSON column type accepts arbitrary JSON, with optional JSON schema validation.
Webhooks
Call a webhook in real-time or trigger a serverless function whenever a record that meets a certain query is created, updated, or deleted.
Self-service import and export
Improved CSV/JSON import capabilities and extended types of data you can import from and export to.
Usage insights
A dashboard that provides valuable insights into your API usage, enabling you to track and analyze your usage more effectively.
Database-level access keys
Secure your data at the database level instead of the workspace. This allows you to add more users to your workspace, and restrict their access and permissions for each database within that workspace.
Changelog
A list of all the small and big changes we've made to the platform at a weekly clip.
May 22, 2023
- Added
createdAtandupdatedAtmeta-columns. From now on, you always know when something was created and last updated. You get them with the record metadata, as simple as that. This was a common feature request that makes developers life easier, which is our favorite type of feature to implement: https://feedback.xata.io/feature-requests/p/implement-createdat-updatedat-fields. It is now also possible to filter by these meta-columns. - Database renames! It sounds simple, but while it was possible to rename almost anything in Xata, database names were forever. Now you can finally fix that typo from the first day of your project. Be aware that this impacts the URLs under which the database is available, so it will be a breaking change to your application.
- Transactions: add
failMissingoption for deletes. If you set this flag to true, and the delete operations affects zero records, the transaction will be failed. - Fix occasional 500 error in the Ask endpoint that happened on particular inputs
- When returning errors about multiple columns, have the columns sorted by name.
- Added a
factoroption to the free-text-search date booster. Thefactormultiplies the boost, allowing you to better control the effect of the date booster. - Better error message on
unique+notNullcolumns. - In the UI, moved database menu functionality to database settings page.
- Bigger scroll target when dragging-and-dropping a column. Makes it easier to move columns around in the table view, especially when having lots of columns.
- For the Vercel integration, redirect to the main page if the user is signed-in already. Fixed a couple more issues around the Vercel integration.
- Handle filter, sort and hidden columns when a column is deleted. This fixes some corner error conditions after a column was deleted.
May 5, 2023
We have launched the all new Xata Workflow: complete git-like workflow for your database. This includes:
- GitHub app that follows your PRs and creates Xata branches for you,
- Vercel integration, making it much easier to connect your Xata DB with your Vercel project,
- Netlify integration and plugin, connecting your Xata DB with your Netlify proejct
- data copying between branches,
- Storing of migration in the repo and CLI pull and push command for schema changes,
- automatic migrations when you merge the Pull Request.
Other fixes and improvements:
- Improved error messages when parsing invalid JSON. Because we obsess over good error messages.
- Fixed renaming of columns and tables when only casing is changed.
- When accepting workspace invitations, treat email addresses case insensitive. This makes it easier to invite your colleagues.
- Fixed border on table cells, making keyboard navigation in the table much easier.
- Fixed the record count after generating random data from the UI.
- Fixed working with hidden linked columns in the UI.
Blog posts:
- XataForm is here! - New open-source project to deal with your forms, survey and quizzes!
- Modern database workflows with GitHub, Vercel, Netlify and Xata - Announce blog post for the new Xata workflow.
- End-to-end preview deployment workflows with Xata and Vercel - Showing our deep Vercel integration.
April 21, 2023
API
- Include the page size in the cursor response metadata. This takes the guessing away and helps troubleshooting.
UI
- Improved previews for cells with a lot of data in them.
- Fixed a small keyboard navigation bug when the columns are reordered and the ID column is no longer the first.
- Improve padding on the cells containing datatime columns to give space for the remove button.
Blogs
- Community spotlight: Accelerating Time-to-Market for Ecommerce Platform Batchoop
April 16, 2023
API
- Improved error message on for null columns without a default value. This is a common source of confusion and, yes, we’re working on fixing better by allowing not null columns without defaults.
UI
- Better confirmation messages when deleting columns or tables. The names of the affected column and table are now included in the confirmation, for example:
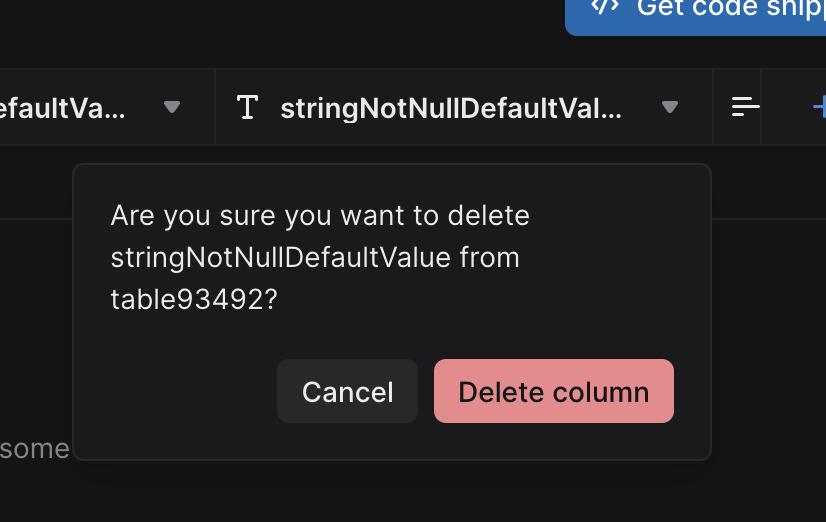
- When canceling an editing operation, we now only show a confirmation dialog if there were any changes.
- The column ordering is now used consistently every where we use it: in the edit drawer, in filters/sorting dialogs, in the schema page, etc.
- Fixed the generated code in the Get Code Snippet that was sometimes producing dates with an invalid format.
- Also fixed an issue where the
'character in filters was producing an error in the Get Code Snippet. - Fixed an issue with editing the ID when adding a new record.
- Fixed scrolling behaviour when renaming or deleting Link columns in the Schema view.
- Sidebar links are now proper
<a>elements so you can right-click and open in a new tab.
Blog posts
- Community spotlight: The story behind xata-go, a Go SDK for Xata
- Search three ways with Xata. This pairs up with the 5 minutes video that visually demonstrates the differences between partial match, fuzzy free-text-search, and semantic/similary search.
March 31, 2023
API
- Do more with less round-trips. Our Transaction API endpoint can now not only
insert,updateanddelete,but alsogetdata by ID. An example looks like this:
{
"operations": [
{"insert": {"table": "items", "record": {"id": "new-0", "name": "feed the fish"}, "createOnly": true}},
{"update": {"table": "items", "id": "new-0", "fields": {"name": "feed the goldfish"}, "ifVersion": 0}},
{"get": {"table": "items", "id": "new-0", "columns": ["id","name"]}},
{"delete": {"table": "items", "id": "new-0"}}
]
}UI
- The “Get Code snippet” dialog is now a lot more helpful to Windows users as we’ve added support for
PowerShellandcmd🎉
- Continuing our theme of quality of life improvements:
- Allow copy pasting of null cell values, because “nulls” are important to developers.
- Improvements in the filtering inputs.
- Fixed a bug where editing emails and numbers was sometimes moving the cursor at the end
Blogs
- Xata and Auth.Js on 2 Next.Js Apps: App Directory and Pages Directory by Atila Fassina
- The Importance of Data Modeling in TypeScript by Fabien Bernard
Podcast
- New Data in the Wild episode: Interview with Anna Maste formerly of Boondockers
Demos
- This twitter thread includes some new things we’re working on.
March 24, 2023
API
- Sometimes all you need is a bit of randomness. A new sort option allows you to “sort by random”. This can be useful, for example, to show a random sample of results from the table. To use, see the examples in the docs. The options looks like this in the API:
{
"sort": ["*:random"]
}And like this in the TypeScript SDK (pending release):
const users = await xata.db.Users
.sort("*", "random")
.getMany();- Fix: in some cases the context passed to ChatGPT was smaller than our target number of tokens, resulting in low quality answers. This is now fixed.
- Fix: drastically reduce the chance of
too_many_nested_clauses****exception on the search and ask endpoints. Also improved the error message to guide towards a correct solution.
UI
- Added the ability to filter on vector columns being NULL.
- Added the ability to paste an datetime into a datetime cell in the grid. e.g.
26/05/18ortomorrow at 4pm - Fixes for the behavior of the Chat bot when them Ask button is pressed multiple times or the tabs are changed.
- Fixed the display of empty strings as a default value in the Schema view.
CLI
- Added support for the vector column to the
xata schema editcommand.
Blog posts
- Semantic Search With Xata, OpenAI, TypeScript, and Deno - A light introduction to using the OpenAI API from TypeScript for a real use case.
- Xata and Auth.js on 2 Next.js Apps: App Directory and Pages Directory - A tutorial showing you how to use the Xata Auth.js adapter to easily implement authentication in Next.js
Docs
- Small changes to Getting Started docs to better reference Python options.
March 17, 2023
API
- Added atomic numeric operations to the update API. They work on the integer and float data types. They can be used, for example, to increment a counter without the risk of race conditions. Docs are in
UI
- New date picker. A new custom-made date picker is used across the UI, solving a set of problems that we had with our previous solution. Among other things, the new date picker supports human input (e.g. “today at 4pm”) and has milliseconds support. The UI is also standardized to always use UTC, for better clarity on what is being stored in the database.

March 10, 2023
API changes
- Update the /ask endpoint to use the new ChatGPT API and the newly released
gpt-3.5-turbomodel. This has resulted in a pricing decrease and more questions included in the free tier. - Fixed error when a lot of nested clauses would cause the /ask endpoint to return 500 errors
- Corrected the license of the published OpenAPI spec to Apache-2
UI changes
- Fixed pasting behaviour when a cell is in edit more. It used to overwrite the whole cell, now it correctly appends to the existing text.
- Several fixes around column constraints:
- Users can set default value without setting
notNull: true - Users can enter invalid constraint combinations but are presented with a clear error about what they did wrong.
- Switching column type resets unique,
notNulland default value to an allowed value if it's unsupported.
- Users can set default value without setting
- Prevent two table cells from being selected in some scenarios. There was a bug when data had changed in the grid and you let your browser tab lose and regain focus.
- Fixed copy paste null string values in table
- More minor cell editing bug fixes
- Small design issues cleanup across the app
- right input padding for table inputs
- clickable table headers in the schema page
- scrollable branch list